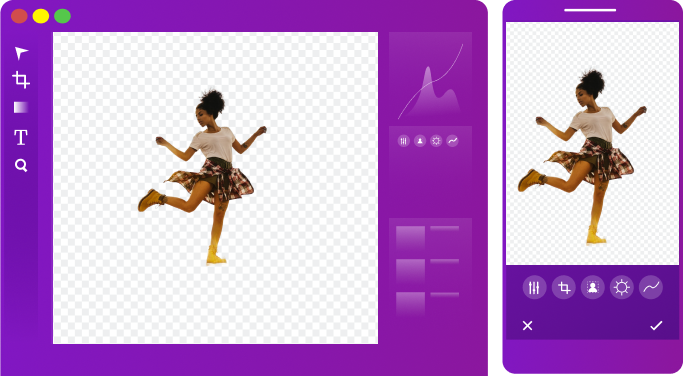
Imran K.
Passionate about leveraging machine learning for solving complex problems and creating impactful products. With a strong background in technical content development, this page serves as a collaborative space for sharing experiences and showcasing a range of projects I have completed.